It's hard enough to find an error in your code when you're looking for it; it's even harder when you've assumed your code is error-free.- Steve McConnell
DynamoDB Free Tier Explained
Recently AWS started charging for Redshift snapshots. I noticed an increase in my AWS bills and decided to dig into the reason. The cost explorer was quite nice, giving me a summary of spending over the past few months.
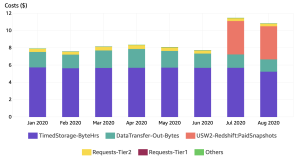
Deleting my snapshot was an easy choice, since this data was used for analytics in my Redditor project and it only contained data up to 2016.
Next, I decided to look into whether I could reduce the DynamoDB monthly costs. This was a mystery to me, since AWS reported that the table only used up 14.6 GB. The free tier allowed up to 25 GB.
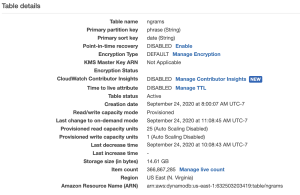
Yet, every month, I was getting billed for an extra 22 GB used. 
After reading the detailed pricing documentation, I found the answer. Amazon explained in their pricing page that, “DynamoDB measures the size of your billable data by adding the raw byte size of the data you upload plus a per-item storage overhead of 100 bytes to account for indexing.” With some simple calculations, I arrived at the same range as my monthly costs:
Item count of 366,867,285 * 100 bytes = 36.6 GB
36.6 – (25 – 14.6) = 25 GB over the free tier limit
While the first free 25 GB was not enough for my use cases, it turned out that AWS allows up to 25 Write Capacity Units (WCUs) and 25 Read Capacity Units (RCUs) of provisioned capacity on the free tier, which is also barely enough for Redditor’s word frequency explorer. I decided to increase the read capacity to 25 RCUs, with each read unit allowing 4 KB of data transfer per second. A typical request to get the counts for word phrases over a period of several years returned about 100 KB of uncompressed data.
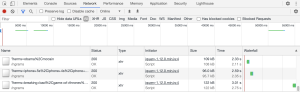
A quick calculation shows that a single request for ngram counts already uses up all of the RCUs alloted for a second!
100 KB / (4KB / s) = 1s (the request takes at least a second on DynamoDB)
As shown in the Chrome network performance tab, the requests took 2-3 seconds.
Solution
The solution for small projects is to use a MySQL key-value table where the time series data is stored in a single column.
--------------------------------------------------------------------------------------------------------------------------------------------+
| key | series |
+---------------------------------------+---------------------------------------------------------------------------------------------------+
| example | 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,34,49,52,62,94,116,77,138,126,175,123...............................|
+---------------------------------------+---------------------------------------------------------------------------------------------------+
This works perfectly for read-only data where the series column does not need to be modified. I used this approach for storing web link frequency counts: https://github.com/yuguang/reddit-comments/tree/master/project. Using some simple Spark code, I filled in the data for missing months as 0 and imported the converted timeseries CSV into MySQL: https://github.com/yuguang/reddit-comments/blob/master/serving_optimization/optimize_timeseries.py. The result is that the response times are now under 150ms!